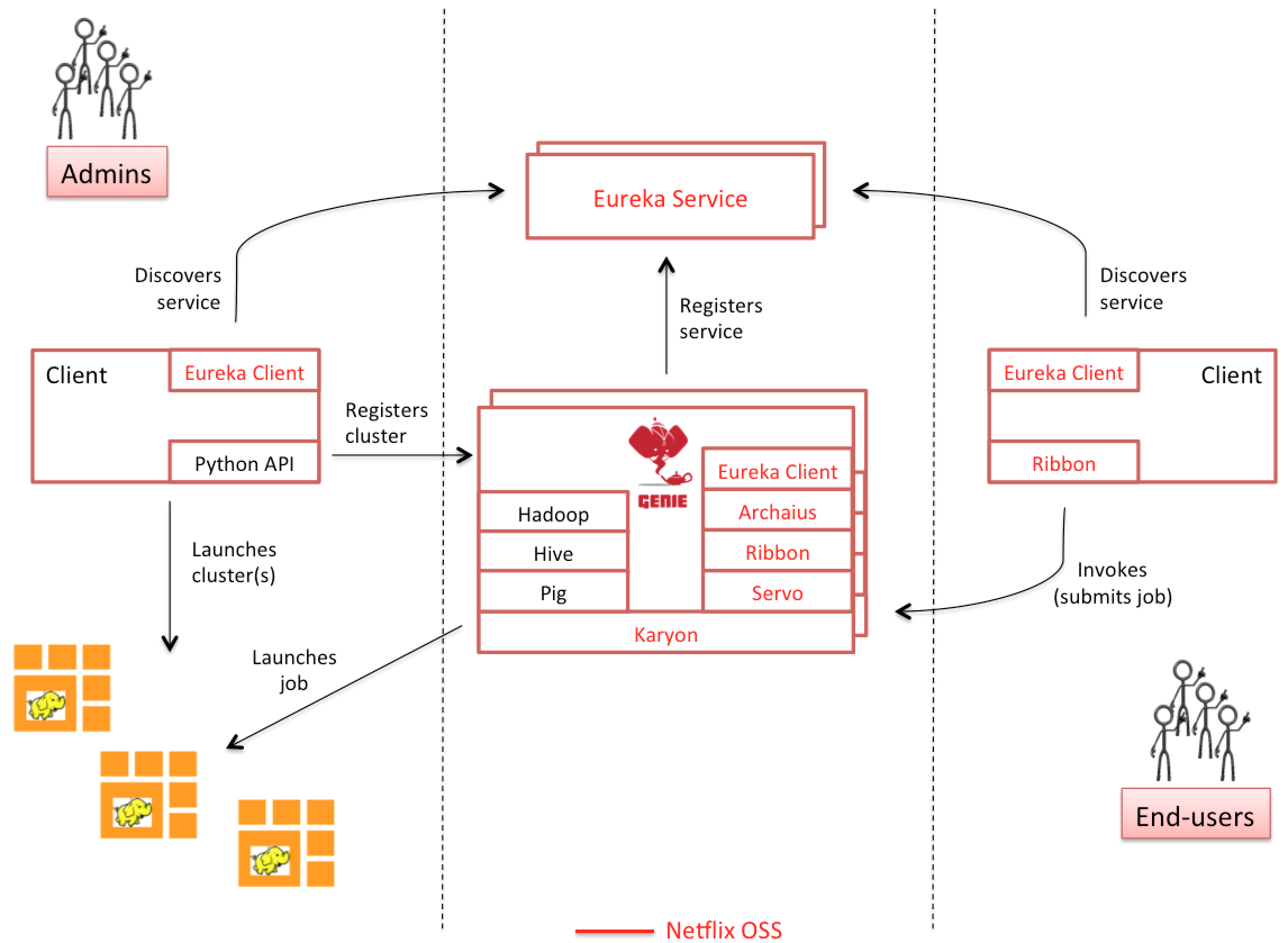
How a job is executed The following diagram explains the core components of Genie, and its two classes of users - administrators,and end-users.
Built on NetflixOSS
Genie itself is built on top of Netflix OSS. At its core, Genie uses the following components:
- Karyon, which provides bootstrapping, runtime insights, diagnostics, and various cloud-ready hooks
- Eureka, which provides service registration and discovery, Although Genie can run in the data-center as well
- Archaius, for dynamic property management in the cloud
- Ribbon, which provides Eureka integration , and client-side load-balancing for REST-ful interprocess communication
- Servo, which enables exporting metrics, registering them with JMX (Java Management Extensions), and publishing them to external monitoring systems such as Amazon’s CloudWatch
Where to Get it
Genie can be downloaded from Maven Central or cloned from Github, built, and deployed into a container such as Tomcat.
Typical Cluster Registration at Netflix
Registration of a cluster with Genie generally follows these steps:
- Administrators first spin up an Execution cluster, e.g. A YARN cluster using the EMR client API.
- Then they decide which clients are needed to run jobs on these clusters.
- eg: Hive/Pig clients for YARN clusters or Presto client for Presto cluster.
- The clients usually are pre-installed on the Genie node unless they can be run simply using a dependency file of some kind (eg: executable jar) which are simple to download at runtime.
- They then upload the configurations for this cluster (*-site.xml’s) and commands to some location on S3.
- Next, the administrators use the Genie client to discover a Genie instance via Eureka (for cloud deployments), and make an API call to register the cluster and commands with Genie.
- After the cluster and commands are registered they are linked together to let Genie know that those commands are available to be run on this cluster.
- Both the clusters and command are registered with sets of tags. The tags are used by users to select the clusters and the commands to run by job submission.
Typical Job Submission at Netflix
After a cluster has been registered, Genie is now ready to grant wishes to its end-users - just as long as their wishes are to submit jobs to run one of the Commands registered with Genie!
End-users use the Genie client to launch and monitor jobs. The client internally uses Eureka to discover a live Genie instance, and Ribbon to perform client-side load balancing, and to communicate REST-fully with the service. Users specify job parameters, which consist of:
- Cluster Tags
- Command Tags
- Command-line arguments for the job,
- A set of file dependencies on S3 that can include scripts or UDFs (user defined functions).
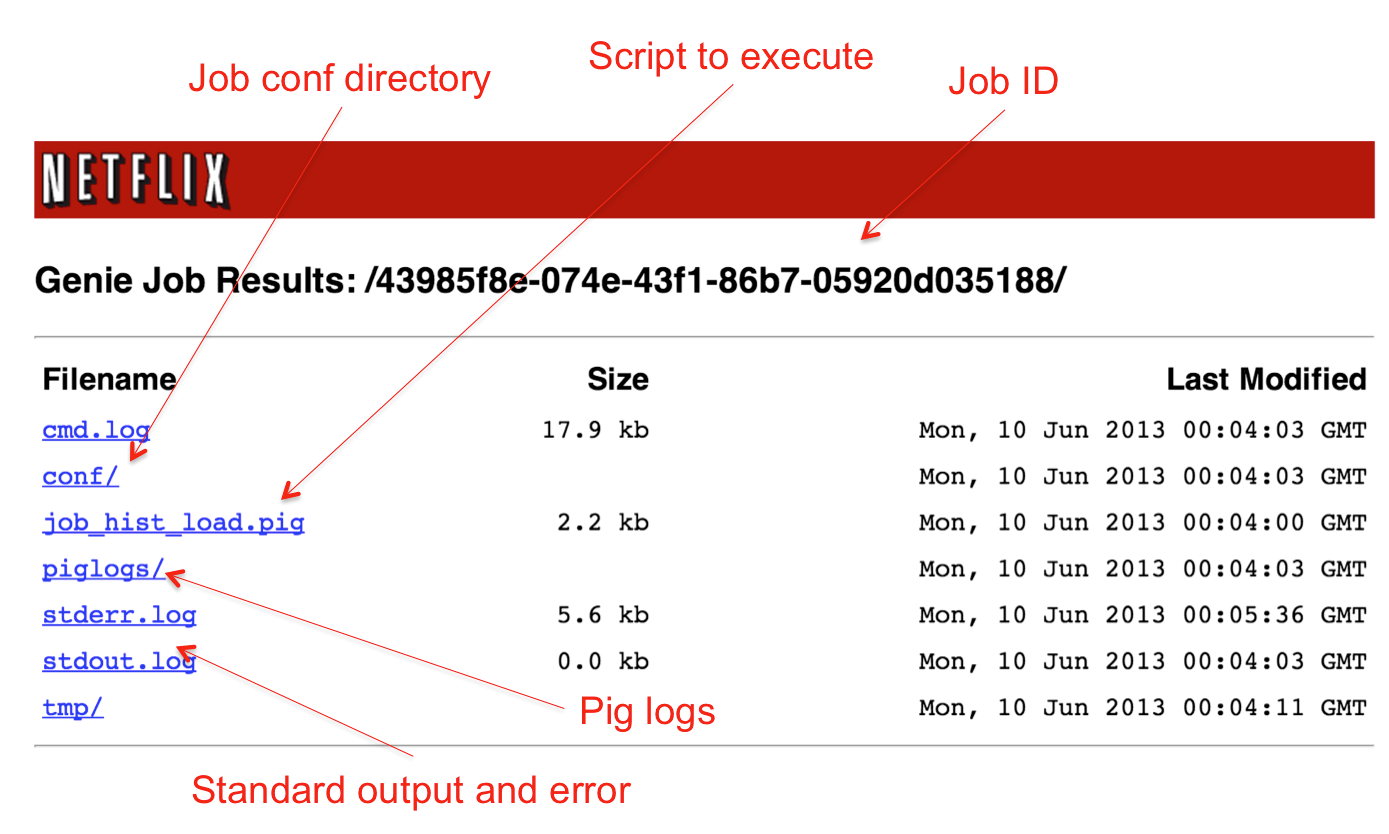
Genie creates a new working directory for each job, stages all the dependencies (including configurations for the chosen cluster and commands), and then forks off a client process from that working directory. It then returns a job ID, which can be used by the clients to query for status, and also to get an output URI, which can be browsed during and after job execution (see below). Users can monitor the standard output and error, and also look at jobs logs, if anything went wrong.