1. Introduction
This is the reference documentation for Genie version 3.0.0. Here you will find high level concept documentation as well as documentation about how to install and configure this Genie version.
| For more Genie information see the website. |
| For documentation of the REST API for this version of Genie please see the API Guide. |
| For a demo of this version of Genie please see the Demo Guide. |
2. Concepts
2.1. Data Model
The Genie 3 data model contains several modifications and additions to the Genie 2 data model to enable even more flexibility, modularity and meta data retention. This section will go over the purpose of the various resources available from the Genie API and how they interact together.
2.1.1. Caveats
-
The specific resource fields are NOT defined in this document. These fields are available in the REST API documentation
2.1.2. Resources
The following sections describe the various resources available from the Genie REST APIs. You should reference the API Docs for how to manipulate these resources. These sections will focus on the high level purposes for each resource and how they rely and/or interact with other resources within the system.
2.1.2.1. Tagging
An important concept is the tagging of resources. Genie relies heavily on tags for how the system discovers resources like clusters and commands for a job. Each of the core resources has a set of tags that can be associated with them. These tags can be of set to whatever you want but it is recommended to come up with some sort of consistent structure for your tags to make it easier for users to understand their purpose. For example at Netflix we’ve adopted some of the following standards for our tags:
-
sched:{something}-
This corresponds to any schedule like that this resource (likely a cluster) is expected to adhere to
-
e.g.
sched:slaorsched:adhoc
-
-
type:{something}-
e.g.
type:yarnortype:prestofor a cluster ortype:hiveortype:sparkfor a command
-
-
ver:{something}-
The specific version of said resource
-
e.g. two different Spark commands could have
ver:1.6.1vsver:2.0.0
-
-
data:{something}-
Used to classify the type of data a resource (usually a command) will access
-
e.g.
data:prodordata:test
-
2.1.2.2. Configuration Resources
The following resources (applications, commands and clusters) are considered configuration, or admin, resources. They’re generally set up by the Genie administrator and available to all users for user with their jobs.
2.1.2.2.1. Application Resource
An application resource represents pretty much what you’d expect. It is a reusable set of binaries, configuration files
and setup files that can be used to install and configure (surprise!) an application. Generally these resources are
used when an application isn’t already installed and on the PATH on a Genie node.
When a job is run and applications are involved in running the job Genie will download all the dependencies, configuration files and setup files of each application and store it all in the job working directory. It will then execute the setup script in order to install that application for that job. Genie is "dumb" as to the contents or purpose of any of these files so the onus is on the administrators to create and test these packages.
Applications are very useful for decoupling application binaries from a Genie deployment. For example you could deploy a Genie cluster and change the version of Hadoop, Hive, Spark that Genie will download without actually re-deploying Genie. Applications can be combined together via a command. This will be explained more in the Command section.
The first entity to talk about is an application. Applications are linked to commands in order for binaries and configurations to be downloaded and installed at runtime. Within Netflix this is frequently used to deploy new clients without redeploying a Genie cluster.
At Netflix our applications frequently consists of a zip of all the binaries uploaded to s3 along with a setup file to unzip and configure environment variables for that application.
It is important to note applications are entirely optional and if you prefer to just install all client binaries on a Genie node beforehand you’re free to do that. It will save in overhead for job launch times but you will lose flexibility in the trade-off.
2.1.2.2.2. Command Resource
Commands resources primarily represent what a user would enter at the command line if you wanted to run a process on a cluster and what dependencies (applications) you would need on your PATH to make that possible.
Commands can have configuration and setup files just like applications but primarily they should have an ordered list of applications associated with them if necessary. For example lets take a typical scenario involving running Hive. To run Hive you generally need a few things:
-
A cluster to run its processing on (we’ll get to that in the Cluster section)
-
A hive-site.xml file which says what metastore to connect to amongst other settings
-
Hive binaries
-
Hadoop configurations and binaries
So a typical setup for Hive in Genie would be to have one, or many, Hive commands configured. Each command would have its own hive-site.xml pointing to a specific metastore (prod, test, etc). The command would depend on Hadoop and Hive applications already configured which would have all the default Hadoop and Hive binaries and configurations. All this would be combined in the job working directory in order to run Hive.
You can have any number of commands configured in the system. They should then be linked to the clusters they can execute on. Clusters are explained next.
2.1.2.2.3. Cluster
A cluster stores all the details of an execution cluster including connection information, properties, etc. Some cluster examples are Hadoop, Spark, Presto, etc. Every cluster can be linked to a set of commands that it can run.
Genie does not launch clusters for you. It merely stores metadata about the clusters you have running in your environment so that jobs using commands and applications can connect to them.
Once a cluster has been linked to commands your Genie instance is ready to start running jobs. The job resources are described in the following section. One important thing to note is that the list of commands linked to the cluster is a priority ordered list. That means if you have two pig commands available on your system for the same cluster the first one found in the list will be chosen provided all tags match. See How it Works for more details.
2.1.2.3. Job Resources
The following resources all relate to a user submitting and monitoring a given job. They are split up from the Genie 2 Job idea to provide better separation of concerns as usually a user doesn’t care about certain things. What node a job ran on or its Linux process exit code for example.
Users interact with these entities directly though all but the initial job request are read-only in the sense you can only get their current state back from Genie.
2.1.2.3.1. Job Request
This is the resource you use to kick off a job. It contains all the information the system needs to run a job. Optionally the REST APIs can take attachments. All attachments and file dependencies are downloaded into the root of the jobs working directory. The most important aspects are the command line arguments, the cluster criteria and the command criteria. These dictate the which cluster, command and arguments will be used when the job is executed. See the How it Works section for more details.
2.1.2.3.2. Job
The job resource is created in the system after a Job Request is received. All the information a typical user would be interested in should be contained within this resource. It has links to the command, cluster and applications used to run the job as well as the meta information like status, start time, end time and others. See the REST API documentation for more details.
2.1.2.3.3. Job Execution
The job execution resource contains information about where a job was run and other information that may be more interesting to a system admin than a regular user. Frequently useful in debugging.
A job contains all the details of a job request and execution including any command line arguments. Based on the request parameters, a cluster and command combination is selected for execution. Job requests can also supply necessary files to Genie either as attachments or using the file dependencies field if they already exist in an accessible file system. As a job executes, its details are recorded in the job record within the Genie database.
2.2. How it Works
This section is meant to provide context for how Genie can be configured with Clusters, Commands and Applications (see Data Model for details) and then how these work together in order to run a job on a Genie node.
2.2.1. Resource Configuration
This section describes how configuration of Genie works from an administrator point of view. This isn’t how to install and configure the Genie application itself. Rather it is how to configure the various resources involved in running a job.
2.2.1.1. Register Resources
All resources (clusters, commands, applications) should be registered with Genie before attempting to link them together. Any files these resources depend on should be uploaded somewhere Genie can access them (S3, web server, mounted disk, etc).
Tagging of the resources, particularly Clusters and Commands, is extremely important. Genie will use the tags in order
to find a cluster/command combination to run a job. You should come up with a convenient tagging scheme for your
organization. At Netflix we try to stick to a pattern for tags structures like {tag category}:{tag value}. For
example type:yarn or data:prod. This allows the tags to have some context so that when users look at what resources
are available they can find what to submit their jobs with so it is routed to the correct cluster/command combination.
2.2.1.2. Linking Resources
Once resources are registered they should be linked together. By linking we mean to represent relationships between the resources.
2.2.1.2.1. Commands for a Cluster
Adding commands to a cluster means that the administrator acknowledges that this cluster can run a given set of commands. If a command is not linked to a cluster it cannot be used to run a job.
The commands are added in priority order. For example say you have different Spark commands you want to add to a given YARN cluster but you want Genie to treat one as the default. Here is how those commands might be tagged:
Spark 1.6.0 (id: spark16)
* type:sparksubmit
* ver:1.6
* ver:1.6.0
Spark 1.6.1 (id: spark161)
* type:sparksubmit
* ver:1.6.1
Spark 2.0.0 (id: spark200)
* type:sparksubmit
* ver:2.0
* ver:2.0.0
Now if we added the commands to the cluster in this order: spark16, spark161, spark200 and a user submitted a job
only requesting a command tagged with type:sparksubmit (as in they don’t care what version just the default) they
would get Spark 1.6.0. However if we later deemed 2.0.0 to be ready to be the default we would reorder the commands to
spark200, spark16, spark161 and that same job if submitted again would now run with Spark 2.0.0.
2.2.1.2.2. Applications for a Command
Linking application(s) to commands means that a command has a dependency on said application(s). The order of the applications added is important because Genie will setup the applications in that order. Meaning if one application depends on another (e.g. Spark depends on Hadoop on classpath for YARN mode) Hadoop should be ordered first. All applications must successfully be installed before Genie will start running the job.
2.2.2. Job Submission
OK. The system admin has everything registered and linked together. Things could obviously change but that’s mostly transparent to end users. They just want to run jobs.How does that work? This section attempts to walk through what happens at a high level. The example section lower down will walk through a step by step example.
2.2.2.1. User Submits a Job Request
In order to submit a job request there is some work a user will have to do up front. What kind of job are they running?
What cluster do they want to run on? What command do they want to use? Do they care about certain details like version
or just want the defaults? Once they determine the answers to the questions they can decide how they want to tag their
job request for the clusterCriterias and commandCriteria fields.
General rule of thumb for these fields is to use the lowest common denominator of tags to accomplish what a user requires. This will allow the most flexibility for the job to be moved to different clusters or commands as need be. For example if they want to run a Spark job and don’t really care about version it is better to just say "type:sparksubmit" (assuming this is tagging structure at your organization) only instead of that and "ver:2.0.0". This way when version 2.0.1 or 2.1.0 comes down the pipe the job moves along with the new default. Obviously if they do care about version they should set it or any other specific tag.
The clusterCriterias field is an array of ClusterCriteria objects. This is done to provide a fallback mechanism. If
the no match is found for the first ClusterCriteria and commandCriteria combination it will move onto the second
and so on until all options are exhausted. This is handy if it is desirable to run a job on some cluster that is only
up some of the time but other times it isn’t and its fine to run it on some other cluster that is always available.
Other things a user needs to consider when submitting a job. All dependencies which aren’t sent as attachments must already be uploaded somewhere Genie can access them. Somewhere like S3, web server, shared disk, etc.
Users should familiarize themselves with whatever the executable for their desired command includes. It’s possible
the system admin has setup some default parameters they should know are there so as to avoid duplication or unexpected
behavior. Also they should make sure they know all the environment variables that may be available to them as part of
the setup process of all the cluster, command and application setup processes.
2.2.2.2. Genie Receives the Job Request
When Genie receives the job request it does a few things immediately:
-
If the job request doesn’t have an id it creates a GUID for the job
-
It saves the job request to the database so it is recorded
-
If the ID is in use a 409 will be returned to the user saying there is a conflict
-
-
It creates job and job execution records in data base for consistency
-
It saves any attachments in a temporary location
Next Genie will attempt to find a cluster and command matching the requested tag combinations. If none is found it will send a failure back to the user and mark the job failed in the database.
If a combination is found Genie will then attempt to determine if the node can run the job. By this it means it will check the amount of client memory the job requires against the available memory in the Genie allocation. If there is enough the job will be accepted and will be run on this node and the jobs memory is subtracted from the available pool. If not it will be rejected with a 503 error message and user should retry later.
The order of priority for how memory for a job is determined is:
-
The memory a user requested in the job request
-
Cannot exceed the max memory allowed by system admin for a given job
-
-
The memory set as the default for a given command by the admins
-
The default memory size for a job as set by the system admin
Successful job submission results in a 202 message to the user stating it’s accepted and will be processed asynchronously by the system.
2.2.2.3. After Job Accepted
Once a job has been accepted to run on a Genie node a workflow is executed in order to setup the job working directory and launch the job. Some minor steps left out for brevity.
-
Job is marked in
INITstate in the database -
A job directory is created under the admin configured jobs directory with a name of the job id
-
A run script file is created with the name
rununder the job working directory-
Currently this is a bash script
-
-
Kill handlers are added to the run script
-
Directories for Genie logs, application files, command files, cluster files are created under the job working directory
-
Default environment variables are added to the run script to export their values
-
Cluster configuration files are downloaded and stored in the job work directory
-
Cluster related variables are written into the run script
-
Application configuration and dependency files are downloaded and stored in the job directory if any applications are needed
-
Application related variables are written into the run script
-
Command configuration and dependency files are downloaded and store in the job directory
-
Command related variables are written into the run script
-
All job dependency files (including attachments) are downloaded into the job working directory
-
Job related variables are written into the run script
-
Job script is executed in a forked process.
-
Script
pidstored in databasejob_executionstable and job marked asRUNNINGin database -
Monitoring process created for pid
2.2.2.4. After Job Running
Once the job is running Genie will poll the PID periodically waiting for it to no longer be used.
| Assumption made as to the amount of process churn on the Genie node. We’re aware PID’s can be reused but reasonably this shouldn’t happen within the poll period given the amount of available PID to the processes a typical Genie node will run. |
Once the pid no longer exists Genie checks the done file for the exit code. It marks the job succeeded, failed or killed depending on that code.
2.2.2.5. Cleaning Up
To save disk space Genie will delete application dependencies from the job working directory after a job is completed.
This can be disabled by an admin. If the job is marked as it should be archived the working directory will be zipped up
and stored in the default archive location under the {jobId}.tar.gz.
2.2.3. User Behavior
Users can check on the status of their job using the status API and get the output using the output APIs. See the
REST Documentation for specifics on how to do that.
2.2.4. Wrap Up
This section should have helped you understand how Genie works at a high level from configuration all the way to user job submission and monitoring. The design of Genie is intended to make this process repeatable and reliable for all users while not hiding any of the details of what is executed at job runtime.
2.3. Netflix Example
Understanding Genie without a concrete example is hard. This section attempts to walk through an end to end configuration and job execution example of a job at Netflix. To see more examples or try your own please see the Demo Guide. Also see the REST API documentation which will describe the purpose of the fields of the resources shown below.
| This example contains JSON representations of resources. |
2.3.1. Configuration
For the purpose of brevity we will only cover a subset of the total Netflix configuration.
2.3.1.1. Clusters
At Netflix there are tens of active clusters available at any given time. For this example we’ll focus on the
production (SLA) and adhoc Hadoop YARN clusters and the production
Presto cluster. For the Hadoop clusters we launch using
Amazon EMR but it really shouldn’t matter how clusters are launched provided you can
access the proper *site.xml files.
The process of launching a YARN cluster at Netflix involves a set of Python tools which interact with the Amazon and Genie APIs. First these tools use the EMR APIs to launch the cluster based on configuration files for the cluster profile. Then the cluster site XML files are uploaded to S3. Once this is complete all the metadata is sent to Genie to create a cluster resource which you can see examples of below.
Presto clusters are launched using Spinnaker on regular EC2 instances. As part of the pipeline the metadata is registered with Genie using the aforementioned Python tools, which in turn leverage the OSS Genie Python Client.
In the following cluster resources you should note the tags applied to each cluster. Remember that the genie.id and
genie.name tags are automatically applied by Genie but all other tags are applied by the admin.
For the YARN clusters note that all the configuration files are referenced by their S3 locations. These files are downloaded into the job working directory at runtime.
2.3.1.1.1. Hadoop Prod Cluster
{
"id": "bdp_h2prod_20161217_205111",
"created": "2016-12-17T21:09:30.845Z",
"updated": "2016-12-20T17:31:32.523Z",
"tags": [
"genie.id:bdp_h2prod_20161217_205111",
"genie.name:h2prod",
"sched:sla",
"ver:2.7.2",
"type:yarn",
"misc:h2bonus3",
"misc:h2bonus2",
"misc:h2bonus1"
],
"version": "2.7.2",
"user": "dataeng",
"name": "h2prod",
"description": null,
"setupFile": null,
"configs": [
"s3://bucket/users/bdp/h2prod/20161217/205111/genie/yarn-site.xml",
"s3://bucket/users/bdp/h2prod/20161217/205111/genie/mapred-site.xml",
"s3://bucket/users/bdp/h2prod/20161217/205111/genie/hdfs-site.xml",
"s3://bucket/users/bdp/h2prod/20161217/205111/genie/core-site.xml"
],
"status": "UP",
"_links": {
"self": {
"href": "https://genieHost/api/v3/clusters/bdp_h2prod_20161217_205111"
},
"commands": {
"href": "https://genieHost/api/v3/clusters/bdp_h2prod_20161217_205111/commands"
}
}
}2.3.1.1.2. Hadoop Adhoc Cluster
{
"id": "bdp_h2query_20161108_204556",
"created": "2016-11-08T21:07:17.284Z",
"updated": "2016-12-07T00:51:19.655Z",
"tags": [
"sched:adhoc",
"misc:profiled",
"ver:2.7.2",
"sched:sting",
"type:yarn",
"genie.name:h2query",
"genie.id:bdp_h2query_20161108_204556"
],
"version": "2.7.2",
"user": "dataeng",
"name": "h2query",
"description": null,
"setupFile": "",
"configs": [
"s3://bucket/users/bdp/h2query/20161108/204556/genie/core-site.xml",
"s3://bucket/users/bdp/h2query/20161108/204556/genie/hdfs-site.xml",
"s3://bucket/users/bdp/h2query/20161108/204556/genie/mapred-site.xml",
"s3://bucket/users/bdp/h2query/20161108/204556/genie/yarn-site.xml"
],
"status": "UP",
"_links": {
"self": {
"href": "https://genieHost/api/v3/clusters/bdp_h2query_20161108_204556"
},
"commands": {
"href": "https://genieHost/api/v3/clusters/bdp_h2query_20161108_204556/commands"
}
}
}2.3.1.1.3. Presto Prod Cluster
{
"id": "presto-prod-v009",
"created": "2016-12-05T19:33:52.575Z",
"updated": "2016-12-05T19:34:14.725Z",
"tags": [
"sched:adhoc",
"genie.id:presto-prod-v009",
"type:presto",
"genie.name:presto",
"ver:0.149",
"data:prod",
"type:spinnaker-presto"
],
"version": "1480966454",
"user": "dataeng",
"name": "presto",
"description": null,
"setupFile": null,
"configs": [],
"status": "UP",
"_links": {
"self": {
"href": "https://genieHost/api/v3/clusters/presto-prod-v009"
},
"commands": {
"href": "https://genieHost/api/v3/clusters/presto-prod-v009/commands"
}
}
}2.3.1.2. Commands
Commands and applications at Netflix are handled a bit differently than clusters. The source data for these command and application resources are not generated dynamically like the cluster configuration files. Instead they are stored in a git repository as a combination of YAML, bash, python and other files. These configuration files are synced to an S3 bucket every time a commit occurs. This makes sure Genie is always pulling in the latest configuration. This sync is performed by a Jenkins job responding to a commit hook trigger. Also done in this Jenkins job is registration of the commands and applications with Genie via the same python tool set and Genie python client as with clusters.
Pay attention to the tags applied to the commands as they are used to select which command to use when a job is run. The presto command includes a setup file which allows additional configuration when it is used.
2.3.1.2.1. Presto 0.149
{
"id": "presto0149",
"created": "2016-08-08T23:22:15.977Z",
"updated": "2016-12-20T23:28:44.678Z",
"tags": [
"genie.id:presto0149",
"type:presto",
"genie.name:presto",
"ver:0.149",
"data:prod",
"data:test"
],
"version": "0.149",
"user": "builds",
"name": "presto",
"description": "Presto Command",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/commands/presto/0.149/setup.sh",
"configs": [],
"status": "ACTIVE",
"executable": "${PRESTO_CMD} --server ${PRESTO_SERVER} --catalog hive --schema default --debug",
"checkDelay": 5000,
"memory": null,
"_links": {
"self": {
"href": "https://genieHost/api/v3/commands/presto0149"
},
"applications": {
"href": "https://genieHost/api/v3/commands/presto0149/applications"
},
"clusters": {
"href": "https://genieHost/api/v3/commands/presto0149/clusters"
}
}
}Presto 0.149 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
chmod 755 ${GENIE_APPLICATION_DIR}/presto0149/dependencies/presto-cli
export JAVA_HOME=/apps/bdp-java/java-8-oracle
export PATH=${JAVA_HOME}/bin/:$PATH
export PRESTO_SERVER="http://${GENIE_CLUSTER_NAME}.rest.of.url"
export PRESTO_CMD=${GENIE_APPLICATION_DIR}/presto0149/dependencies/presto-wrapper.py
chmod 755 ${PRESTO_CMD}2.3.1.2.2. Spark Submit Prod 1.6.1
{
"id": "prodsparksubmit161",
"created": "2016-05-17T16:38:31.152Z",
"updated": "2016-12-20T23:28:33.042Z",
"tags": [
"genie.id:prodsparksubmit161",
"genie.name:prodsparksubmit",
"ver:1.6",
"type:sparksubmit",
"data:prod",
"ver:1.6.1"
],
"version": "1.6.1",
"user": "builds",
"name": "prodsparksubmit",
"description": "Prod Spark Submit Command",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/commands/spark/1.6.1/prod/scripts/spark-1.6.1-prod-submit-cmd.sh",
"configs": [
"s3://bucket/builds/bdp-cluster-configs/genie3/commands/spark/1.6.1/prod/configs/hive-site.xml"
],
"status": "ACTIVE",
"executable": "${SPARK_HOME}/bin/dsespark-submit",
"checkDelay": 5000,
"memory": null,
"_links": {
"self": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit161"
},
"applications": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit161/applications"
},
"clusters": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit161/clusters"
}
}
}Spark Submit Prod 1.6.1 Setup File
#!/bin/bash
#set -o errexit -o nounset -o pipefail
export JAVA_HOME=/apps/bdp-java/java-8-oracle
#copy hive-site.xml configuration
cp ${GENIE_COMMAND_DIR}/config/* ${SPARK_CONF_DIR}
cp ${GENIE_COMMAND_DIR}/config/* ${HADOOP_CONF_DIR}/2.3.1.2.3. Spark Submit Prod 2.0.0
{
"id": "prodsparksubmit200",
"created": "2016-10-31T16:59:01.145Z",
"updated": "2016-12-20T23:28:47.340Z",
"tags": [
"ver:2",
"genie.name:prodsparksubmit",
"ver:2.0",
"genie.id:prodsparksubmit200",
"ver:2.0.0",
"type:sparksubmit",
"data:prod"
],
"version": "2.0.0",
"user": "builds",
"name": "prodsparksubmit",
"description": "Prod Spark Submit Command",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/commands/spark/2.0.0/prod/copy-config.sh",
"configs": [
"s3://bucket/builds/bdp-cluster-configs/genie3/commands/spark/2.0.0/prod/configs/hive-site.xml"
],
"status": "ACTIVE",
"executable": "${SPARK_HOME}/bin/dsespark-submit.py",
"checkDelay": 5000,
"memory": null,
"_links": {
"self": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit200"
},
"applications": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit200/applications"
},
"clusters": {
"href": "https://genieHost/api/v3/commands/prodsparksubmit200/clusters"
}
}
}Spark Submit 2.0.0 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
# copy hive-site.xml configuration
cp ${GENIE_COMMAND_DIR}/config/* ${SPARK_CONF_DIR}2.3.1.3. Applications
Below are the applications needed by the above commands. The most important part of these applications are the dependencies and the setup file.
The dependencies are effectively the installation package and at Netflix typically are a zip of all binaries needed to run a client like Hadoop, Hive, Spark etc. Some of these zips are generated by builds and placed in S3 and others are downloaded from OSS projects and uploaded to S3 periodically. Often minor changes to these dependencies are needed. A new file is uploaded to S3 and the Genie caches on each node will be refreshed with this new file on next access. This pattern allows us to avoid replacing Genie clusters every time an application changes.
The setup file effectively is the installation script for the aforementioned dependencies. It is sourced by Genie and the expectation is that after it is run the application is successfully configured in the job working directory.
2.3.1.3.1. Hadoop 2.7.2
{
"id": "hadoop272",
"created": "2016-08-18T16:58:31.044Z",
"updated": "2016-12-21T00:01:08.263Z",
"tags": [
"type:hadoop",
"genie.id:hadoop272",
"genie.name:hadoop",
"ver:2.7.2"
],
"version": "2.7.2",
"user": "builds",
"name": "hadoop",
"description": "Hadoop Application",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/applications/hadoop/2.7.2/setup.sh",
"configs": [],
"dependencies": [
"s3://bucket/hadoop/2.7.2/hadoop-2.7.2.tgz"
],
"status": "ACTIVE",
"type": "hadoop",
"_links": {
"self": {
"href": "https://genieHost/api/v3/applications/hadoop272"
},
"commands": {
"href": "https://genieHost/api/v3/applications/hadoop272/commands"
}
}
}Hadoop 2.7.2 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
export JAVA_HOME=/apps/bdp-java/java-7-oracle
export APP_ID=hadoop272
export APP_NAME=hadoop-2.7.2
export HADOOP_DEPENDENCIES_DIR=$GENIE_APPLICATION_DIR/$APP_ID/dependencies
export HADOOP_HOME=$HADOOP_DEPENDENCIES_DIR/$APP_NAME
tar -xf "${HADOOP_DEPENDENCIES_DIR}/hadoop-2.7.2.tgz" -C "${HADOOP_DEPENDENCIES_DIR}"
export HADOOP_CONF_DIR="${HADOOP_HOME}/conf"
export HADOOP_LIBEXEC_DIR="${HADOOP_HOME}/usr/lib/hadoop/libexec"
export HADOOP_HEAPSIZE=1500
cp ${GENIE_CLUSTER_DIR}/config/* $HADOOP_CONF_DIR/
EXTRA_PROPS=$(echo "<property><name>genie.job.id</name><value>$GENIE_JOB_ID</value></property><property><name>genie.job.name</name><value>$GENIE_JOB_NAME</value></property><property><name>lipstick.uuid.prop.name</name><value>genie.job.id</value></property><property><name>dataoven.job.id</name><value>$GENIE_JOB_ID</value></property><property><name>genie.netflix.environment</name><value>${NETFLIX_ENVIRONMENT:-prod}</value></property><property><name>genie.version</name><value>$GENIE_VERSION</value></property><property><name>genie.netflix.stack</name><value>${NETFLIX_STACK:-none}</value></property>" | sed 's/\//\\\//g')
sed -i "/<\/configuration>/ s/.*/${EXTRA_PROPS}&/" $HADOOP_CONF_DIR/core-site.xml
if [ -d "/apps/s3mper/hlib" ]; then
export HADOOP_OPTS="-javaagent:/apps/s3mper/hlib/aspectjweaver-1.7.3.jar ${HADOOP_OPTS:-}"
fi
# Remove the zip to save space
rm "${HADOOP_DEPENDENCIES_DIR}/hadoop-2.7.2.tgz"2.3.1.3.2. Presto 0.149
{
"id": "presto0149",
"created": "2016-08-08T23:21:58.780Z",
"updated": "2016-12-21T00:21:10.945Z",
"tags": [
"genie.id:presto0149",
"type:presto",
"genie.name:presto",
"ver:0.149"
],
"version": "0.149",
"user": "builds",
"name": "presto",
"description": "Presto Application",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/applications/presto/0.149/setup.sh",
"configs": [],
"dependencies": [
"s3://bucket/presto/clients/0.149/presto-cli",
"s3://bucket/builds/bdp-cluster-configs/genie3/applications/presto/0.149/presto-wrapper.py"
],
"status": "ACTIVE",
"type": "presto",
"_links": {
"self": {
"href": "https://genieProd/api/v3/applications/presto0149"
},
"commands": {
"href": "https://genieProd/api/v3/applications/presto0149/commands"
}
}
}Presto 0.149 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
chmod 755 ${GENIE_APPLICATION_DIR}/presto0149/dependencies/presto-cli
chmod 755 ${GENIE_APPLICATION_DIR}/presto0149/dependencies/presto-wrapper.py
export JAVA_HOME=/apps/bdp-java/java-8-oracle
export PATH=${JAVA_HOME}/bin/:$PATH
# Set the cli path for the commands to use when they invoke presto using this Application
export PRESTO_CLI_PATH="${GENIE_APPLICATION_DIR}/presto0149/dependencies/presto-cli"2.3.1.3.3. Spark 1.6.1
{
"id": "spark161",
"created": "2016-05-17T16:32:21.475Z",
"updated": "2016-12-21T00:01:07.951Z",
"tags": [
"genie.id:spark161",
"type:spark",
"ver:1.6",
"ver:1.6.1",
"genie.name:spark"
],
"version": "1.6.1",
"user": "builds",
"name": "spark",
"description": "Spark Application",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/applications/spark/1.6.1/scripts/spark-1.6.1-app.sh",
"configs": [
"s3://bucket/builds/bdp-cluster-configs/genie3/applications/spark/1.6.1/configs/spark-env.sh"
],
"dependencies": [
"s3://bucket/spark/1.6.1/spark-1.6.1.tgz"
],
"status": "ACTIVE",
"type": "spark",
"_links": {
"self": {
"href": "https://genieHost/api/v3/applications/spark161"
},
"commands": {
"href": "https://genieHost/api/v3/applications/spark161/commands"
}
}
}Spark 1.6.1 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
VERSION="1.6.1"
DEPENDENCY_DOWNLOAD_DIR="${GENIE_APPLICATION_DIR}/spark161/dependencies"
# Unzip all the Spark jars
tar -xf ${DEPENDENCY_DOWNLOAD_DIR}/spark-${VERSION}.tgz -C ${DEPENDENCY_DOWNLOAD_DIR}
# Set the required environment variable.
export SPARK_HOME=${DEPENDENCY_DOWNLOAD_DIR}/spark-${VERSION}
export SPARK_CONF_DIR=${SPARK_HOME}/conf
export SPARK_LOG_DIR=${GENIE_JOB_DIR}
export SPARK_LOG_FILE=spark.log
export SPARK_LOG_FILE_PATH=${GENIE_JOB_DIR}/${SPARK_LOG_FILE}
export CURRENT_JOB_WORKING_DIR=${GENIE_JOB_DIR}
export CURRENT_JOB_TMP_DIR=${CURRENT_JOB_WORKING_DIR}/tmp
export JAVA_HOME=/apps/bdp-java/java-8-oracle
export SPARK_DAEMON_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
# Make Sure Script is on the Path
export PATH=$PATH:${SPARK_HOME}/bin
# Delete the zip to save space
rm ${DEPENDENCY_DOWNLOAD_DIR}/spark-${VERSION}.tgzSpark 1.6.1 Environment Variable File
#!/bin/bash
#set -o errexit -o nounset -o pipefail
export JAVA_HOME=/apps/bdp-java/java-8-oracle
export SPARK_DAEMON_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"2.3.1.3.4. Spark 2.0.0
{
"id": "spark200",
"created": "2016-10-31T16:58:54.155Z",
"updated": "2016-12-21T00:01:11.105Z",
"tags": [
"type:spark",
"ver:2.0",
"ver:2.0.0",
"genie.id:spark200",
"genie.name:spark"
],
"version": "2.0.0",
"user": "builds",
"name": "spark",
"description": "Spark Application",
"setupFile": "s3://bucket/builds/bdp-cluster-configs/genie3/applications/spark/2.0.0/setup.sh",
"configs": [],
"dependencies": [
"s3://bucket/spark-builds/2.0.0/spark-2.0.0.tgz"
],
"status": "ACTIVE",
"type": "spark",
"_links": {
"self": {
"href": "https://genieHost/api/v3/applications/spark200"
},
"commands": {
"href": "https://genieHost/api/v3/applications/spark200/commands"
}
}
}Spark 2.0.0 Setup File
#!/bin/bash
set -o errexit -o nounset -o pipefail
start_dir=`pwd`
cd `dirname ${BASH_SOURCE[0]}`
SPARK_BASE=`pwd`
cd $start_dir
export JAVA_HOME=/apps/bdp-java/java-8-oracle
export SPARK_DAEMON_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
SPARK_DEPS=${SPARK_BASE}/dependencies
export SPARK_VERSION="2.0.0"
tar xzf ${SPARK_DEPS}/spark-${SPARK_VERSION}.tgz -C ${SPARK_DEPS}
# Set the required environment variable.
export SPARK_HOME=${SPARK_DEPS}/spark-${SPARK_VERSION}
export SPARK_CONF_DIR=${SPARK_HOME}/conf
export SPARK_LOG_DIR=${GENIE_JOB_DIR}
export SPARK_LOG_FILE=spark.log
export SPARK_LOG_FILE_PATH=${GENIE_JOB_DIR}/${SPARK_LOG_FILE}
export CURRENT_JOB_WORKING_DIR=${GENIE_JOB_DIR}
export CURRENT_JOB_TMP_DIR=${CURRENT_JOB_WORKING_DIR}/tmp
# Make Sure Script is on the Path
export PATH=$PATH:${SPARK_HOME}/bin
# Delete the tarball to save space
rm ${SPARK_DEPS}/spark-${SPARK_VERSION}.tgz
chmod a+x ${SPARK_HOME}/bin/dsespark-submit.py2.3.1.4. Relationships
Now that all the resources are available they need to be linked together. Commands need to be added to the clusters they can be run on and applications need to be added as dependencies for commands.
2.3.1.4.1. Commands for a Cluster
When commands are added to a cluster they should be in priority order. Meaning if two commands both match a users tags for a job the one higher in the list will be used. This allows us to switch defaults quickly and transparently.
Note: The lists below leave out a lot of commands and fields for brevity. Only the id of the command is included so it can reference the same command resource defined earlier in this article.
Hadoop Prod Cluster
The Hadoop clusters have both currently supported Spark versions added. Spark 1.6.1 is the default but users can
override to Spark 2 using the ver tag.
[
...
{
"id": "prodsparksubmit161"
...
},
{
"id": "prodsparksubmit200"
...
}
...
]Hadoop Adhoc Cluster
[
...
{
"id": "prodsparksubmit161"
...
},
{
"id": "prodsparksubmit200"
...
}
...
]Presto Prod Cluster
Presto clusters only really support the Presto command but possible that it could have multiple backwards compatible versions of the client available.
[
...
{
"id": "presto0149"
...
}
...
]2.3.1.4.2. Applications for a Command
Linking applications to a command tells Genie that these applications need to be downloaded and setup in order to successfully run the command. The order of the applications will be the order the download and setup is performed so dependencies between applications should be managed via this order.
Presto 0.149
Presto only needs the corresponding Presto application which contains the Presto Java CLI jar and some setup wrapper scripts.
[
{
"id": "presto0149"
...
}
]Spark Submit Prod 1.6.1
Since we submit Spark jobs to YARN clusters in order to run the Spark submit commands we need both Spark and Hadoop applications installed and configured on the job classpath in order to run. Hadoop needs to be setup first so that the configurations can be copied to Spark.
[
{
"id": "hadoop272"
...
},
{
"id": "spark161"
...
}
]Spark Submit Prod 2.0.0
[
{
"id": "hadoop272"
...
},
{
"id": "spark200"
...
}
]2.3.2. Job Submission
Everything is now in place for users to submit their jobs. This section will walk through the components and outputs of that process. For clarity we’re going to show a PySpark job being submitted to show how Genie figures out the cluster and command to be used based on what was configured above.
2.3.2.1. The Request
Below is an actual job request (with a few obfuscations) made by a production job here at Netflix to Genie.
{
"id": "SP.CS.FCT_TICKET_0054500815", (1)
"created": "2016-12-21T04:13:07.244Z",
"updated": "2016-12-21T04:13:07.244Z",
"tags": [ (2)
"submitted.by:call_genie",
"scheduler.job_name:SP.CS.FCT_TICKET",
"scheduler.run_id:0054500815",
"SparkPythonJob",
"scheduler.name:uc4"
],
"version": "NA",
"user": "someNetflixEmployee",
"name": "SP.CS.FCT_TICKET",
"description": "{\"username\": \"root\", \"host\": \"2d35f0d397fd\", \"client\": \"nflx-kragle-djinn/0.4.3\", \"kragle_version\": \"0.41.11\", \"job_class\": \"SparkPythonJob\"}",
"setupFile": null,
"commandArgs": "--queue root.sla --py-files dea_pyspark_core-latest.egg fct_ticket.py", (3)
"clusterCriterias": [ (4)
{
"tags": [
"sched:sla"
]
}
],
"commandCriteria": [ (5)
"type:sparksubmit",
"data:prod"
],
"group": null,
"disableLogArchival": false,
"email": null,
"cpu": null,
"memory": null,
"timeout": null,
"dependencies": [ (6)
"s3://bucket/DSE/etl_code/cs/ticket/fct_ticket.py",
"s3://bucket/dea/pyspark_core/dea_pyspark_core-latest.egg"
],
"applications": [],
"_links": {
"self": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/request"
},
"job": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815"
},
"execution": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/execution"
},
"output": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/output"
},
"status": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/status"
}
}
}Lets look at a few of the fields of note:
| 1 | The user set the ID. This is a popular pattern in Netflix for tracking jobs between systems and reattaching to jobs. |
| 2 | The user added a few tags that will allow them to search for the job later. This is optional but convenient. |
| 3 | The user specifies some arguments to add to the default set of command arguments specified by the command
executable field. In this case it’s what python file to run. |
| 4 | The user wants this job to run on any cluster that is labeled as having an SLA which also supports the command
selected using the commandCriteria |
| 5 | User wants the default Spark Submit command (no version specified) and wants to be able to access production data |
| 6 | Here you can see that they add the two files referenced in the commandArgs as dependencies. These files will be
downloaded in the root job directory parallel to the run script so they are accessible. |
2.3.2.2. The Job
In this case the job was accepted by Genie for processing. Below is the actual job object containing fields the user might care about. Some are copied from the initial request (like tags) and some are added by Genie.
{
"id": "SP.CS.FCT_TICKET_0054500815",
"created": "2016-12-21T04:13:07.245Z",
"updated": "2016-12-21T04:20:35.801Z",
"tags": [
"submitted.by:call_genie",
"scheduler.job_name:SP.CS.FCT_TICKET",
"scheduler.run_id:0054500815",
"SparkPythonJob",
"scheduler.name:uc4"
],
"version": "NA",
"user": "someNetflixEmployee",
"name": "SP.CS.FCT_TICKET",
"description": "{\"username\": \"root\", \"host\": \"2d35f0d397fd\", \"client\": \"nflx-kragle-djinn/0.4.3\", \"kragle_version\": \"0.41.11\", \"job_class\": \"SparkPythonJob\"}",
"status": "SUCCEEDED", (1)
"statusMsg": "Job finished successfully.", (2)
"started": "2016-12-21T04:13:09.025Z", (3)
"finished": "2016-12-21T04:20:35.794Z", (4)
"archiveLocation": "s3://bucket/genie/main/logs/SP.CS.FCT_TICKET_0054500815.tar.gz", (5)
"clusterName": "h2prod", (6)
"commandName": "prodsparksubmit", (7)
"runtime": "PT7M26.769S", (8)
"commandArgs": "--queue root.sla --py-files dea_pyspark_core-latest.egg fct_ticket.py",
"_links": {
"self": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815"
},
"output": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/output"
},
"request": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/request"
},
"execution": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/execution"
},
"status": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/status"
},
"cluster": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/cluster"
},
"command": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/command"
},
"applications": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/applications"
}
}
}Some fields of note:
| 1 | The current status of the job. Since this sample was taken after the job was completed it’s already marked SUCCESSFUL |
| 2 | This job was successful but if it failed for some reason a more human readable reason would be found here |
| 3 | The time this job was forked from the Genie process |
| 4 | The time Genie recognized the job as complete |
| 5 | Where Genie uploaded a zip of the job directory after the job was completed |
| 6 | The name of the cluster where this job ran and is de-normalized from the cluster record at the time |
| 7 | The name of the command used to run this job which is de-normalized from the command record at the time |
| 8 | The total run time in ISO8601 |
2.3.2.2.1. Cluster Selection
Because the user submitted with sched:sla this limits the clusters it can run on to any with that tag applied. In our
example case only the cluster with ID bdp_h2prod_20161217_205111 has this tag. This isn’t enough to make sure this
job can run (there also needs to be a matching command). If there had been multiple sla clusters Genie would consider
them all equal and randomly select one.
2.3.2.2.2. Command Selection
The command criteria states that this job needs to run on a SLA cluster that supports a command of type
prodsparksubmit that can access prod data. Two commands (prodsparksubmit161 and prodsparksubmit200) match this
criteria. Both are linked to the cluster bdp_h2prod_20161217_205111. Since both match Genie selects the "default" one
which is the first on in the list. In this case it was prodsparksubmit161.
2.3.2.3. The Job Execution
Below is the job execution resource. This is mainly for system and admin use but it can have some useful information for users as well. Mainly it shows which Genie node it actually ran on, how much memory it was allocated, how frequently the system polled it for status and when it would have timed out had it kept running.
{
"id": "SP.CS.FCT_TICKET_0054500815",
"created": "2016-12-21T04:13:07.245Z",
"updated": "2016-12-21T04:20:35.801Z",
"hostName": "a.host.com",
"processId": 68937,
"checkDelay": 5000,
"timeout": "2016-12-28T04:13:09.016Z",
"exitCode": 0,
"memory": 1536,
"_links": {
"self": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/execution"
},
"job": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815"
},
"request": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/request"
},
"output": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/output"
},
"status": {
"href": "https://genieHost/api/v3/jobs/SP.CS.FCT_TICKET_0054500815/status"
}
}
}2.3.2.4. Job Output
Below is an image of the root of the job output directory (displayed via Genie UI) for the above job. Note that the dependency files are all downloaded there and some standard files are available (run, stdout, stderr).
| The URI’s in this section point to the UI output endpoint however they are also available via the REST API and the UI is really calling this REST API to get the necessary information. Showing the UI endpoints for the better looking output and because most users will see this version. |
| Click image for full size |
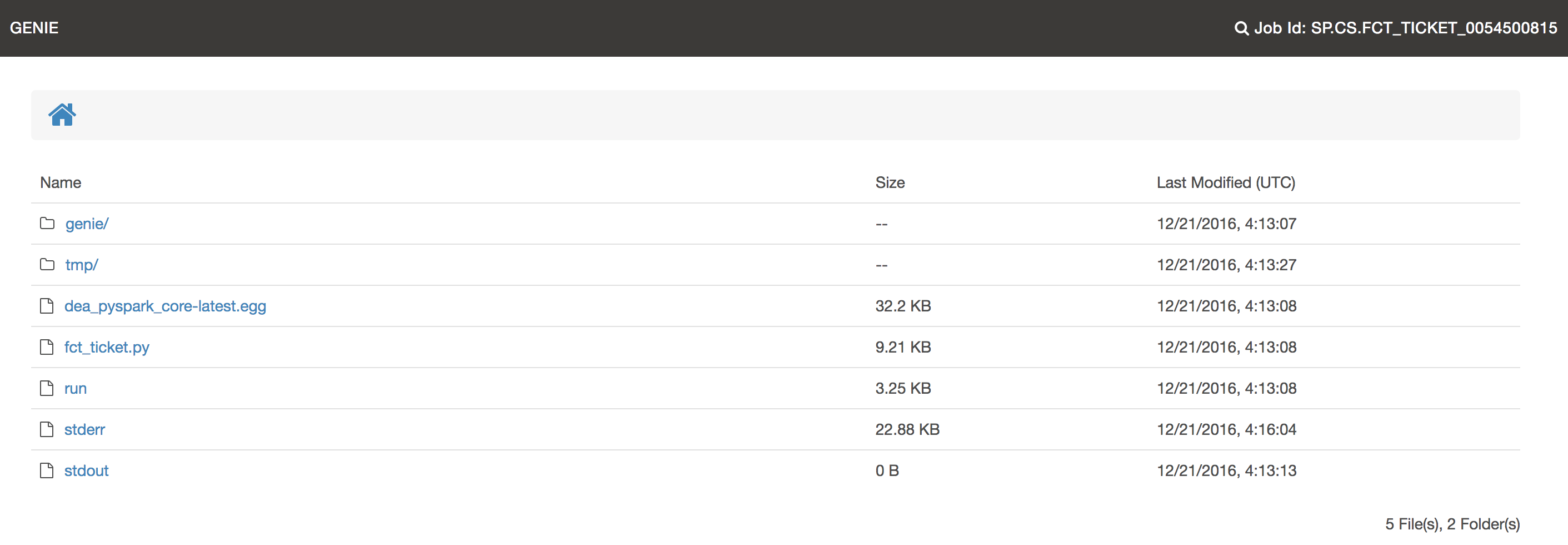
2.3.2.4.1. The Run Script
Clicking into the run script shows the below contents. This run script is generated specifically for each individual
job by Genie. It has some standard bits (error checking, exit process) but also specific information like environment
variables and what to actually run. Everything is specific to the job working directory. In particular note all the
GENIE_* environment variable exports. These can be used when building your setup and configuration scripts to be more
flexible.
#!/usr/bin/env bash
set -o nounset -o pipefail
# Set function in case any of the exports or source commands cause an error
trap "handle_failure" ERR EXIT
function handle_failure {
ERROR_CODE=$?
# Good exit
if [[ ${ERROR_CODE} -eq 0 ]]; then
exit 0
fi
# Bad exit
printf '{"exitCode": "%s"}\n' "${ERROR_CODE}" > ./genie/genie.done
exit "${ERROR_CODE}"
}
# Set function for handling kill signal from the job kill service
trap "handle_kill_request" SIGTERM
function handle_kill_request {
KILL_EXIT_CODE=999
# Disable SIGTERM signal for the script itself
trap "" SIGTERM
echo "Kill signal received"
### Write the kill exit code to genie.done file as exit code before doing anything else
echo "Generate done file with exit code ${KILL_EXIT_CODE}"
printf '{"exitCode": "%s"}\n' "${KILL_EXIT_CODE}" > ./genie/genie.done
### Send a kill signal the entire process group
echo "Sending a kill signal to the process group"
pkill -g $$
COUNTER=0
NUM_CHILD_PROCESSES=`pgrep -g ${SELF_PID} | wc -w`
# Waiting for 30 seconds for the child processes to die
while [[ $COUNTER -lt 30 ]] && [[ "$NUM_CHILD_PROCESSES" -gt 3 ]]; do
echo The counter is $COUNTER
let COUNTER=COUNTER+1
echo "Sleeping now for 1 seconds"
sleep 1
NUM_CHILD_PROCESSES=`pgrep -g ${SELF_PID} | wc -w`
done
# check if any children are still running. If not just exit.
if [ "$NUM_CHILD_PROCESSES" -eq 3 ]
then
echo "Done"
exit
fi
### Reaching at this point means the children did not die. If so send kill -9 to the entire process group
# this is a hard kill and will this process itself as well
echo "Sending a kill -9 to children"
pkill -9 -g $$
echo "Done"
}
SELF_PID=$$
echo Start: `date '+%Y-%m-%d %H:%M:%S'`
export GENIE_JOB_DIR="/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815"
export GENIE_APPLICATION_DIR="${GENIE_JOB_DIR}/genie/applications"
export GENIE_COMMAND_DIR="${GENIE_JOB_DIR}/genie/command/prodsparksubmit161"
export GENIE_COMMAND_ID="prodsparksubmit161"
export GENIE_COMMAND_NAME="prodsparksubmit"
export GENIE_CLUSTER_DIR="${GENIE_JOB_DIR}/genie/cluster/bdp_h2prod_20161217_205111"
export GENIE_CLUSTER_ID="bdp_h2prod_20161217_205111"
export GENIE_CLUSTER_NAME="h2prod"
export GENIE_JOB_ID="SP.CS.FCT_TICKET_0054500815"
export GENIE_JOB_NAME="SP.CS.FCT_TICKET"
export GENIE_JOB_MEMORY=1536
export GENIE_VERSION=3
# Sourcing setup file from Application: hadoop272
source ${GENIE_JOB_DIR}/genie/applications/hadoop272/setup.sh
# Sourcing setup file from Application: spark161
source ${GENIE_JOB_DIR}/genie/applications/spark161/spark-1.6.1-app.sh
# Sourcing setup file from Command: prodsparksubmit161
source ${GENIE_JOB_DIR}/genie/command/prodsparksubmit161/spark-1.6.1-prod-submit-cmd.sh
# Dump the environment to a env.log file
env | sort > ${GENIE_JOB_DIR}/genie/logs/env.log
# Kick off the command in background mode and wait for it using its pid
${SPARK_HOME}/bin/dsespark-submit --queue root.sla --py-files dea_pyspark_core-latest.egg fct_ticket.py > stdout 2> stderr &
wait $!
# Write the return code from the command in the done file.
printf '{"exitCode": "%s"}\n' "$?" > ./genie/genie.done
echo End: `date '+%Y-%m-%d %H:%M:%S'`2.3.2.4.2. Genie Dir
Inside the output directory there is a genie directory. This directory is where Genie stores all the downloaded
dependencies and any logs. Everything outside this directory is intended to be user generated other than the run
script. Some commands or applications may put their logs in the root directory as well if desired (like spark or hive
logs).
| Click image for full size |
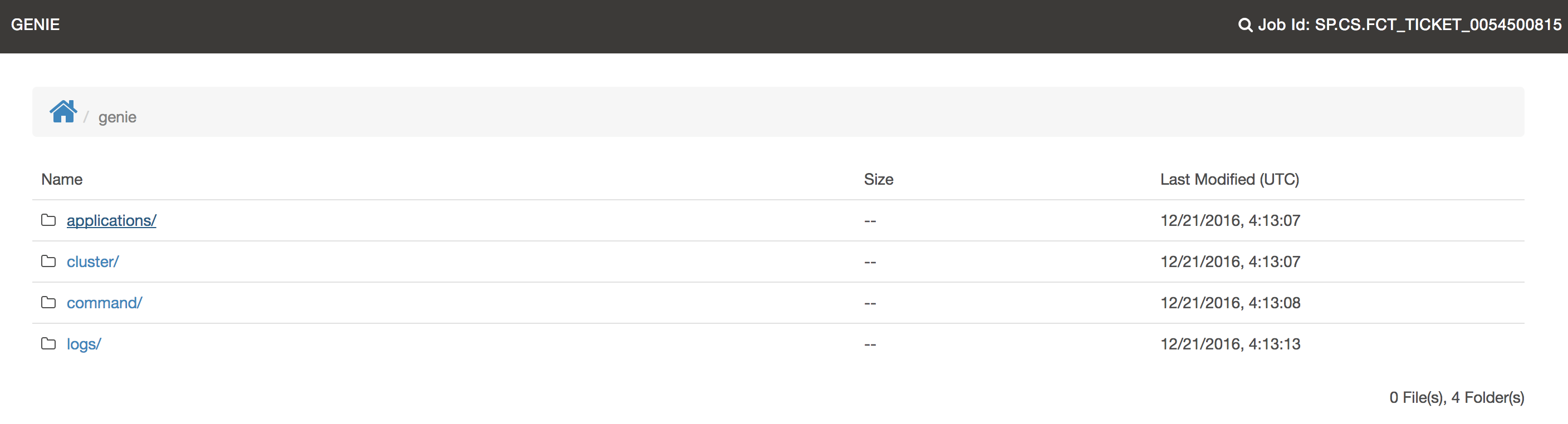
Genie system logs go into the logs directory.
| Click image for full size |
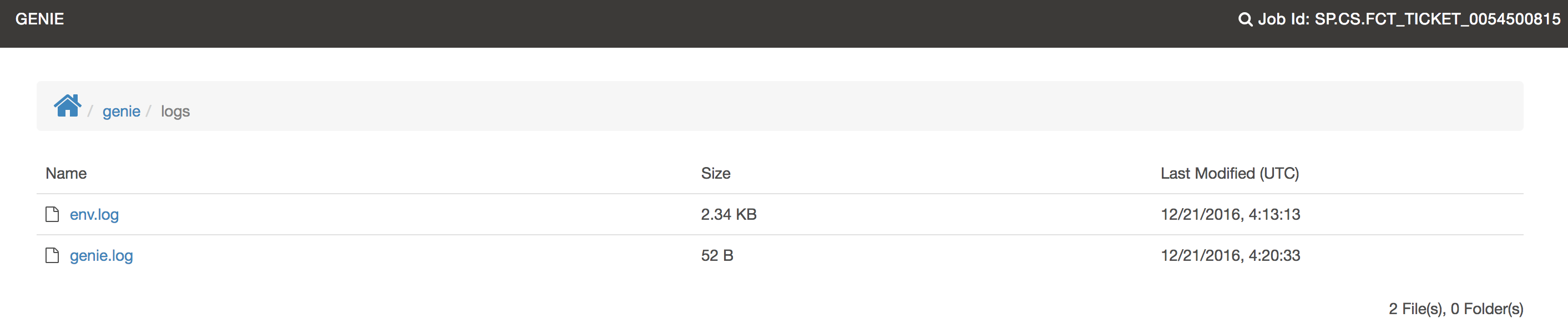
Of interest in here is the env dump file. This is convenient for debugging jobs. You can see all the environment variables that were available right before Genie executed the final command to run the job in the run script.
You can see this file generated in the run script above on this line:
# Dump the environment to a env.log file
env | sort > ${GENIE_JOB_DIR}/genie/logs/env.logThe contents of this file will look something like the below
APP_ID=hadoop272
APP_NAME=hadoop-2.7.2
CURRENT_JOB_TMP_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/tmp
CURRENT_JOB_WORKING_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815
EC2_AVAILABILITY_ZONE=us-east-1d
EC2_REGION=us-east-1
GENIE_APPLICATION_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications
GENIE_CLUSTER_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/cluster/bdp_h2prod_20161217_205111
GENIE_CLUSTER_ID=bdp_h2prod_20161217_205111
GENIE_CLUSTER_NAME=h2prod
GENIE_COMMAND_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/command/prodsparksubmit161
GENIE_COMMAND_ID=prodsparksubmit161
GENIE_COMMAND_NAME=prodsparksubmit
GENIE_JOB_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815
GENIE_JOB_ID=SP.CS.FCT_TICKET_0054500815
GENIE_JOB_MEMORY=1536
GENIE_JOB_NAME=SP.CS.FCT_TICKET
GENIE_VERSION=3
HADOOP_CONF_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/hadoop272/dependencies/hadoop-2.7.2/conf
HADOOP_DEPENDENCIES_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/hadoop272/dependencies
HADOOP_HEAPSIZE=1500
HADOOP_HOME=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/hadoop272/dependencies/hadoop-2.7.2
HADOOP_LIBEXEC_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/hadoop272/dependencies/hadoop-2.7.2/usr/lib/hadoop/libexec
HOME=/home/someNetflixUser
JAVA_HOME=/apps/bdp-java/java-8-oracle
LANG=en_US.UTF-8
LOGNAME=someNetflixUser
MAIL=/var/mail/someNetflixUser
NETFLIX_ENVIRONMENT=prod
NETFLIX_STACK=main
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin:/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/spark161/dependencies/spark-1.6.1/bin
PWD=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815
SHELL=/bin/bash
SHLVL=1
SPARK_CONF_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/spark161/dependencies/spark-1.6.1/conf
SPARK_DAEMON_JAVA_OPTS=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
SPARK_HOME=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/genie/applications/spark161/dependencies/spark-1.6.1
SPARK_LOG_DIR=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815
SPARK_LOG_FILE_PATH=/mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/spark.log
SPARK_LOG_FILE=spark.log
SUDO_COMMAND=/usr/bin/setsid /mnt/genie/jobs/SP.CS.FCT_TICKET_0054500815/run
SUDO_GID=60243
SUDO_UID=60004
SUDO_USER=genie
TERM=unknown
TZ=GMT
USER=someNetflixUser
USERNAME=someNetflixUser
_=/usr/bin/envFinally inside the applications folder you can see the applications that were downloaded and configured.
| Click image for full size |

| Click image for full size |
2.3.3. Wrap Up
This section went over how Genie is configured by admins at Netflix and how how users submit jobs and retrieve their logs and output. Anyone is free to configure Genie however suits their needs in terms of tags and applications which are downloaded vs installed already on a Genie node but this method works for us here at Netflix.
2.4. Netflix Deployment
Many people ask how Genie is deployed at Netflix on AWS. This section tries to explain at a high level the components used and how Genie integrates into the environment. Below is a diagram of how deployment looks at Netflix.
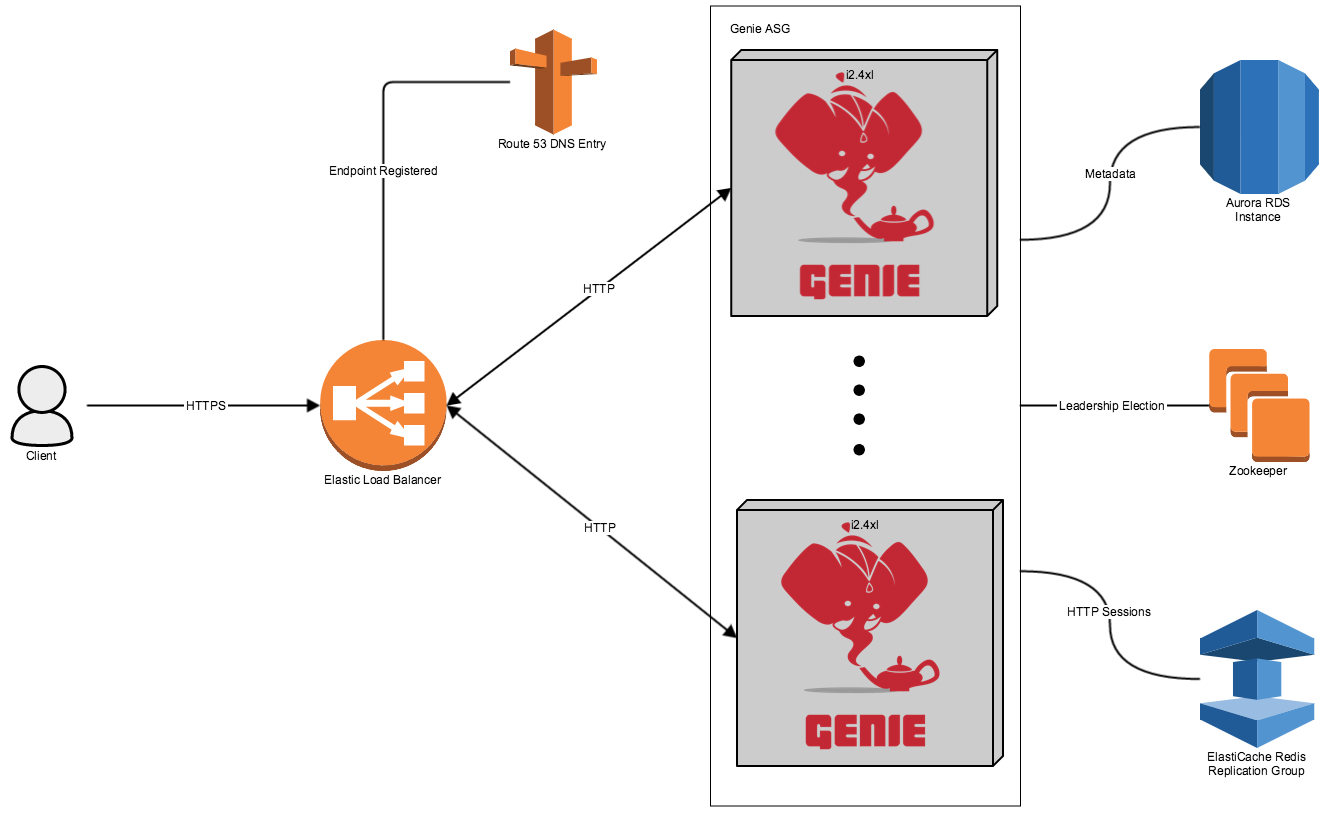
2.4.1. Components
Brief descriptions of all the components.
2.4.1.1. Elastic Load Balancer
The Elastic Load Balancer (ELB) is used for a few purposes.
-
Allow a single endpoint for all API calls
-
Distribute API calls amongst all Genie nodes in an ASG
-
Allow HTTPS termination at single point
-
Allow human friendly DNS name to be assigned via Route 53 entry
2.4.1.2. Auto Scaling Group (ASG)
Currently the Genie ASG is a fleet of i2.4xl instances. The primary production ASG sizes about thirty instances at any given time. Each Genie instance is configured to be allocated 80% of the available system memory for jobs. Tomcat itself is given 10 GB. Leaving the rest for the system and other processes.
The ASG is set to auto scale when the average amount of used job memory, that 80% of the system memory, exceeds 60% of the available.
For example an i2.4xl image has 122 GB of available memory. For simplicity we allocate 100 GB for jobs. If the average memory used for jobs per node across the ASG exceeds 60 GB for some period of time we will scale the cluster up by one node to allocate resources before we get in trouble.
Currently we don’t auto scale down but from time to time we take a look to see if a new ASG needs to be launched at a smaller size.
2.4.1.3. Relational Database (RDS)
We currently use an Amazon Aurora cluster on db.r3.4xl instances. Aurora is MySQL compatible so we use the standard MySQL JDBC driver that is packaged with Genie to talk to the database. We deploy to a Multi-AZ cluster and we have a reader endpoint that we use for reporting and backup.
2.4.1.4. Zookeeper
We use an Apache Zookeeper cluster which is deployed and managed by another team within Netflix for leadership election within our Genie ASG. When the Genie ASG comes up it (using Spring Cloud Cluster) looks in Zookeeper to see if there already is a leader for the app/cluster/stack combination. If there isn’t it elects a new one.
2.4.1.5. ElastiCache
We use AWS ElastiCache to provide a Redis cluster to store our HTTP sessions (via Spring Session). This allows us to have the users only sign in via SAML one time and not have to do it every time the ELB routes them to a new host for the UI.
2.4.1.6. Security Configuration
Internally Genie is secured via OAuth2 (for APIs) and SAML (for UI). We integrate with a Ping Federate IDP service to provide authentication and authorization information.
HTTPS is enabled to the ELB via a Verisign signed certificate tied to the Route 53 DNS address.
See Security for more information.
2.4.1.7. Spinnaker
Genie is deployed using Spinnaker. We currently have a few stacks (prod, test, dev, load, stage, etc) that we use for different purposes. Spinnaker handles all this for us after we configure the pipelines. See the Spinnaker site for more information.
2.5. Security
A long requested feature for Genie has been adding authentication and authorization support for the UI and particularly the REST APIs. Genie 3 development allowed the time and resources to finally implement a solution. Genie security is built on top of Spring Security which allows the specific security solution to be plugged in based on user requirements.
2.5.1. Architecture
Out of the box Genie supports securing the REST APIs via OAuth2 and/or x509 certificates and the UI via SAML. Below is an image of how this security architecture works within Netflix.

At a high level you can see that the requests are passed through several security filter chains before they arrive at the Genie application code. Based on the URL being accessed different filter chains will be triggered. If the request can be authenticated and authorized the security configuration is stored within the Spring Security Context which can then be accessed via Genie code if necessary.
All the security can be enabled or disabled as desired by system administrators. You can find the various properties
under genie.security.* in the Properties section. Spring specific properties are also involved but the enabling
and disabling is done via the genie.security properties.
2.5.2. REST API Security
The REST APIs described in the REST documentation can be
secured via OAuth2 and/or x509 out of the box. Both these mechanisms secure everything under /api/* to require a user
be authenticated to access them. All job and read (e.g. GET) APIs are available to any authenticated user when
security is enabled. If security is enabled users will need to be granted an admin role in order to use the
configuration APIs for applications, commands and clusters. By configuration APIs we mean anything that will
modify the state of these resources like the POST, PUT, PATCH, DELETE APIs.
2.5.2.1. x509
If x509 is enabled it will be checked first (before the OAuth2 filter chain if that is enabled) and if a valid certificate is present in the request the user will be authenticated and granted the pertinent role.
For this to work out of the box the certicates must be formatted so that the principle field contains a colon
separated string of format {user}:{role1,role2…}. This is how Genie will determine the user and roles that user
will be granted within the system.
2.5.2.2. OAuth2
OAuth2 security is implemented via the Spring Security OAuth project. You can read documentation there but out of the box support has been extended to include Ping Federate as a provider. This is used within Netflix and there are two ways you can have Genie validate tokens. One is if the Bearer token is merely and identifier you can have Genie call the Ping Federate server to validate the Bearer token is valid. The other is to configure Ping Federate to generated JWT tokens and all validation can be done within the Genie node. This is the preferrable option as you save processing time and unnecessary IO.
2.5.3. UI Security
The UI and other endpoints can be secured using SAML via Spring SAML. You can configure Genie where to look in the SAML assertion to parse out user and role information. If only SAML security is turned on users won’t need to authenticate in order to access the APIs. If SAML and one of the REST API security methods is enabled and configured if a user authenticates to the UI via SAML they will also be able to access the REST APIs within the same HTTP session without aquiring a token or passing a certificate.
2.5.4. Wrap Up
This section is meant to provide a high level overview of how Genie supports authentication and authorization out of the box if configured properly. Security is a very large topic and to truly understand how this works reading into the various libraries and technologies mentioned in this section is recommended.
3. Installation
Installing Genie is easy. You can run Genie either as a standalone application with an embedded Tomcat or by deploying the WAR file to an existing Tomcat or other servlet container. There are trade-offs to these two methods as will be discussed below.
3.1. Standalone Jar
The
standalone jar
is the simplest to deploy as it has no other real moving parts. Just
put the jar somewhere on a system and execute java -jar genie-app-3.0.0.jar. The downside is it’s a little
harder to configure or add jars to the classpath if you want them.
Configuration (application*.yml or application*.properties) files can be loaded from the current working directory or
from a .genie/ directory stored in the users home directory (e.g. ~/.genie/application.yml). Classpath items (jars,
.jks files, etc) can be added to ~/.genie/lib/ and they will be part of the application classpath.
Properties can be passed in on the command line two ways:
-
java -Dgenie.example.property blah -jar genie-app-3.0.0.jar -
java -jar genie-app-3.0.0.jar --genie.example.property=blah
Property resolution goes in this order:
-
Command line
-
Classpath profile specific configuration files (e.g. application-prod.yml)
-
Embedded profile specific configuration files
-
Classpath default configuration file (e.g. application.yml)
-
Embedded default configuration file
For more details see the Spring Boot documentation on external configuration.
3.2. Tomcat Deployment
The WAR deployment requires the
WAR file
be placed in an existing Tomcat or servlet
container. At Netflix we use this method as we have existing tuning of Tomcat and a lot of infrastructure in place
for monitoring of the Tomcat process. We deploy to Tomcat 8.x and rename the WAR file to ROOT.war so that the
application context root is /.
The benefits of deploying to Tomcat are you have more access to the internals of the application and can change property files directly or add classpath items to either the Tomcat classpath or in the actual Genie lib directory.
The drawback is that you now also have to tune and configure Tomcat or your chosen servlet container in addition to Genie and it may be more overhead than you’re comfortable with.
3.3. Configuration
Genie has a lot of available configuration options. For descriptions of specific properties you can see the Properties section below. Additionally if you want to know how to configure more parts of the application you should have a look at the Spring Boot docs as they will go in depth on how to configure the various Spring components used in Genie.
3.3.1. Profiles
Spring provides a mechanism of segregating parts of application configuration and activating them in certain
conditions. This mechanism is known as
profiles. By default
Genie will run with the dev profile activated. This means that all the properties in application-dev.yml will be
appended to, or overwrite, the properties in application.yml which are the defaults. Changing the active profiles is
easy you just need to change the property spring.profiles.active and pass in a comma separated list of active
profiles. For example --spring.profiles.active=prod,cloud would activate the prod and cloud profiles.
Properties for specific profiles should be stored in files named application-{profileName}.yml. You can make as many
as you want but Genie ships with dev, s3 and prod profiles properties already included. Their properties can be
seen in the Properties section below.
3.3.2. Database
By default since Genie will launch with the dev profile active it will launch with an in memory database running as
part of its process. This means when you shut Genie down all data will be lost. It is meant for development only. Genie
ships with JDBC drivers for MySql, PostgreSQL and HSQLDB. If you want to use a different database you should load
the JDBC driver jar file somewhere on the Genie classpath.
For production you should probably enable the prod profile which creates a connection pool for the database and then
override the properties spring.datasource.url, spring.datasource.username and spring.datasource.password to match
your environment. The datasource url needs to be a valid JDBC connection string for your database. You can see examples
here or
here or search for your database
and JDBC connection string on your search engine of choice.
Genie also ships with database schema scripts for MySQL and PostgreSQL. You will need to load these into your database before you run Genie if you use one of these databases. Genie no longer creates the schema dynamically for performance reasons. Follow the below sections to load the schemas into your table.
| There exist Genie 2.x to Genie 3.x migration scripts for MySQL and PostgreSQL but it is recommended to start from scratch if you can. See the source code for the migration scripts if you want to try to use them. |
3.3.2.1. MySQL
| This assumes the MySQL client binaries are installed |
Download the MySQL Schema. Then run:
mysql -u {username} -p{password} -h {host} -e 'create database genie;'
mysql -u {username} -p{password} -h {host} genie < 3.0.0-schema.mysql.sql3.3.2.2. PostgreSQL
| This assumes the PSQL binaries are installed |
Download the PostgreSQL Schema Then run:
createdb genie
psql -U {user} -h {host} -d genie -f 3.0.0-schema.postgresql.sql3.3.3. Local Directories
Genie requires a few directories to run. By default Genie will place them under /tmp however in production you should
probably create a larger directory you can store the job working directories and other places in. These correspond to
the genie.jobs.locations.* properties described below in the Properties section.
3.4. Wrap Up
This section contains the basic setup instructions for Genie. There are other components that can be added to the system like Redis, Zookeeper and Security systems that are somewhat outside the scope of an initial setup. You can see the Properties section below for the properties you’d need to configure for these systems.
4. Properties
This section describes the various properties that can be set to control the behavior of your Genie node and cluster. For more information on Spring properties you should see the Spring Boot reference documentation. The Spring properties described here are ones that we have overridden from Spring defaults.
4.1. Default Properties
4.1.1. Genie Properties
| Property | Description | Default Value |
|---|---|---|
genie.file.cache.location |
Where to store cached files on local disk |
|
genie.health.maxCpuLoadConsecutiveOccurrences |
Defines the threshold of consecutive occurrences of CPU load crossing the <maxCpuLoadPercent>. Health of the system is marked unhealthy if the CPU load of a system goes beyond the threshold 'maxCpuLoadPercent' for 'maxCpuLoadConsecutiveOccurrences' consecutive times. |
3 |
genie.health.maxCpuLoadPercent |
Defines the threshold for the maximum CPU load percentage to consider for an instance to be unhealthy. Health of the system is marked unhealthy if the CPU load of a system goes beyond this threshold for 'maxCpuLoadConsecutiveOccurrences' consecutive times. |
80 |
genie.http.connect.timeout |
The number of milliseconds before HTTP calls between Genie nodes should time out on connection |
2000 |
genie.http.read.timeout |
The number of milliseconds before HTTP calls between Genie nodes should time out on attempting to read data |
10000 |
genie.jobs.cleanup.deleteArchiveFile |
Whether to delete the job directory zip after it has been backed up to save disk space |
true |
genie.jobs.cleanup.deleteDependencies |
Whether or not to delete the dependencies directories for applications to save disk space after job completion |
true |
genie.jobs.forwarding.enabled |
Whether or not to attempt to forward kill and get output requests for jobs |
true |
genie.jobs.forwarding.port |
The port to forward requests to as it could be different than ELB port |
8080 |
genie.jobs.forwarding.scheme |
The connection protocol to use (http or https) |
http |
genie.jobs.locations.archives |
The default root location where job archives should be stored. Scheme should be included. Created if doesn’t exist. |
|
genie.jobs.locations.attachments |
The default root location where job attachments will be temporarily stored. Scheme should be included. Created if doesn’t exist. |
|
genie.jobs.locations.jobs |
The default root location where job working directories will be placed. Created by system if doesn’t exist. |
|
genie.jobs.max.stdOutSize |
The maximum number of bytes the job standard output file can grow to before Genie will kill the job |
8589934592 |
genie.jobs.max.stdErrSize |
The maximum number of bytes the job standard error file can grow to before Genie will kill the job |
8589934592 |
genie.jobs.memory.maxSystemMemory |
The total number of MB out of the system memory that Genie can use for running jobs |
30720 |
genie.jobs.memory.defaultJobMemory |
The total number of megabytes Genie will assume a job is allocated if not overridden by a command or user at runtime |
1024 |
genie.jobs.memory.maxJobMemory |
The maximum amount of memory, in megabytes, that a job client can be allocated |
10240 |
genie.jobs.users.creationEnabled |
Whether Genie should attempt to create a system user in order to run the job as or not. Genie user must have sudo rights for this to work. |
false |
genie.jobs.users.runAsUserEnabled |
Whether Genie should run the jobs as the user who submitted the job or not. Genie user must have sudo rights for this to work. |
false |
genie.leader.enabled |
Whether this node should be the leader of the cluster or not. Should only be used if leadership is not being determined by Zookeeper or other mechanism via Spring |
false |
genie.mail.fromAddress |
The e-mail address that should be used as the from address when alert emails are sent |
|
genie.mail.user |
The user to log into the e-mail server with |
|
genie.mail.password |
The password for the e-mail server |
|
genie.redis.enabled |
Whether to enable storage of HTTP sessions inside Redis via Spring Session |
false |
genie.retry.initialInterval |
The amount of time to wait after initial failure before retrying the first time in milliseconds |
10000 |
genie.retry.maxInterval |
The maximum amount of time to wait between retries for the final retry in the back-off policy |
60000 |
genie.retry.noOfRetries |
The number of times to retry requests to before failure |
5 |
genie.retry.s3.noOfRetries |
The number of times to retry requests to S3 before failure |
5 |
genie.security.oauth2.enabled |
Whether to enable oauth2 based security or not for REST APIs |
false |
genie.security.oauth2.pingfederate.enabled |
Whether Ping Federate is being used as the OAuth2 server and Genie should assume default configuration for its tokens |
false |
genie.security.oauth2.pingfederate.jwt.enabled |
Whether to assume that the bearer tokens coming with API requests are JWT tokens or not |
false |
genie.security.oauth2.pingfederate.jwt.keyValue |
The public key used to verify the JWT signature |
|
genie.security.saml.enabled |
Whether SAML security should be turned on to protect access to the user interface |
false |
genie.security.saml.attributes.user |
The key in the SAML assertion to get the user name from |
|
genie.security.saml.attributes.groups.name |
The key in the SAML assertion to get group information for the user from |
|
genie.security.saml.attributes.groups.admin |
The group a user needs to be a member of in order to be granted an admin role |
|
genie.security.saml.idp.serviceProviderMetadataUrl |
The URL where metadata for Genie service SAML configuration can be pulled from |
|
genie.security.saml.keystore.name |
The name of the keystore file on the classpath for SAML assertions |
|
genie.security.saml.keystore.password |
The password for opening the keystore |
|
genie.security.saml.keystore.defaultKey.name |
The name of the default key to use for signing the SAML request |
|
genie.security.saml.keystore.defaultKey.password |
The password to open the default key |
|
genie.security.saml.loadBalancer.contextPath |
The context path for Genie |
/ |
genie.security.saml.loadBalancer.includeServerPortInRequestURL |
Whether or not to include the port of the load balancer in the redirect request |
false |
genie.security.saml.loadBalancer.scheme |
The scheme the load balancer Genie cluster is run behind uses (http or https). Used for SAML post back |
|
genie.security.saml.loadBalancer.serverName |
Root context for the Genie load balancer e.g. genie.prod.com |
|
genie.security.saml.loadBalancer.serverPort |
The port the load balancer is listening on. Used for SAML post back |
|
genie.security.saml.sp.entityId |
The id that Genie is identified by in the identity provider |
|
genie.security.saml.sp.entityBaseURL |
Where the SAML assertion should be posted back to. e.g. https://genie.prod.com |
|
genie.security.x509.enabled |
Whether to enable x509 certificate security on the REST APIs |
false |
genie.swagger.enabled |
Whether to enable Swagger to be bootstrapped into the Genie service so that the endpoint /swagger-ui.html shows API documentation generated by the swagger specification |
false |
genie.tasks.clusterChecker.healthIndicatorsToIgnore |
The health indicator groups from the actuator /health endpoint to ignore when determining if a node is lost or not as a comma separated list |
memory,genie,discoveryComposite |
genie.tasks.clusterChecker.lostThreshold |
The number of times a Genie nodes need to fail health check in order for jobs running on that node to be marked as lost and failed by the Genie leader |
3 |
genie.tasks.clusterChecker.port |
The port to connect to other Genie nodes on |
8080 |
genie.tasks.clusterChecker.rate |
The number of milliseconds to wait between health checks to other Genie nodes |
300000 |
genie.tasks.clusterChecker.scheme |
The scheme (http or https) for connecting to other Genie nodes |
http |
genie.tasks.databaseCleanup.enabled |
Whether or not to delete old job records from the database |
true |
genie.tasks.databaseCleanup.expression |
The cron expression for how often to run the database cleanup task |
0 0 0 * * * |
genie.tasks.databaseCleanup.retention |
The number of days to retain jobs in the database |
90 |
genie.tasks.diskCleanup.enabled |
Whether or not to remove old job directories on the Genie node or not |
true |
genie.tasks.diskCleanup.expression |
How often to run the disk cleanup task as a cron expression |
0 0 0 * * * |
genie.tasks.diskCleanup.retention |
The number of days to leave old job directories on disk |
3 |
genie.tasks.executor.pool.size |
The number of executor threads available for tasks to be run on within the node in an adhoc manner. Best to set to the number of CPU cores x 2 + 1 |
1 |
genie.tasks.scheduler.pool.size |
The number of available threads for the scheduler to use to run tasks on the node at scheduled intervals. Best to set to the number of CPU cores x 2 + 1 |
1 |
4.1.2. Spring Properties
| Property | Description | Default Value |
|---|---|---|
banner.location |
Banner file location |
genie-banner.txt |
eureka.client.enabled |
Whether to create a eureka client or not |
false |
eureka.client.serviceUrl.defaultZone |
The URL of the Eureka service |
|
eureka.client.register-with-eureka |
Whether or not to register this Genie node with the Eureka service. Will only happen if the |
true |
info.genie.version |
The Genie version to be displayed by the UI and returned by the actuator /info endpoint. Set by the build. |
Current build version |
management.context-path |
Where the actuator endpoints are mounted within the Genie application |
/actuator |
management.security.enabled |
Whether to enable basic security on the actuator endpoints |
false |
multipart.max-file-size |
Max attachment file size. Values can use the suffixed "MB" or "KB" to indicate a Megabyte or Kilobyte size. |
100MB |
multipart.max-request-size |
Max job request size. Values can use the suffixed "MB" or "KB" to indicate a Megabyte or Kilobyte size. |
200MB |
security.basic.enabled |
Enable basic authentication |
false |
security.oauth2.client.client-id |
The id of the OAuth2 client |
|
security.oauth2.client.client-secret |
The secret for the oauth2 client |
|
security.oauth2.resource.id |
Id of the resource server |
|
security.oauth2.resource.token-info-uri |
URI where to get token information from |
|
spring.application.name |
The name of the application in the Spring context |
genie |
spring.cloud.cluster.leader.enabled |
Whether to enable leadership election via Spring Cloud Cluster. Means a zookeeper endpoint needs to be available |
false |
spring.cloud.cluster.zookeeper.connect |
Comma separated list of Zookeeper nodes to connect to for leadership election |
|
spring.cloud.cluster.zookeeper.namespace |
The znode namespace to use for Genie leadership election of a given cluster |
/genie/leader/ |
spring.jackson.date-format |
Date format string or a fully-qualified date format class name. For instance |
com.netflix.genie.common.util.GenieDateFormat |
spring.jackson.time-zone |
Time zone used when formatting dates. For instance |
UTC |
spring.profiles.active |
The default active profiles when Genie is run |
dev |
spring.mail.host |
The hostname of the mail server |
|
spring.mail.testConnection |
Whether to check the connection to the mail server on startup |
false |
spring.redis.host |
Endpoint for the Redis cluster used to store HTTP session information |
|
spring.velocity.enabled |
Whether velocity should be enabled for Spring MVC |
false |
4.2. Profile Specific Properties
4.2.1. Dev Profile
| Property | Description | Default Value |
|---|---|---|
spring.jpa.hibernate.ddl-auto |
DDL mode. This is actually a shortcut for the "hibernate.hbm2ddl.auto" property. Default to "create-drop" when using an embedded database, "none" otherwise. |
update |
spring.jpa.hibernate.naming-strategy |
Naming strategy fully qualified name. |
org.hibernate.cfg.ImprovedNamingStrategy |
spring.datasource.url |
JDBC URL of the database |
jdbc:hsqldb:mem:genie-db;shutdown=true |
spring.datasource.username |
Username for the datasource |
SA |
spring.datasource.password |
Database password |
4.2.2. Prod Profile
| Property | Description | Default Value |
|---|---|---|
spring.datasource.url |
JDBC URL of the database |
jdbc:mysql://127.0.0.1/genie |
spring.datasource.username |
Username for the datasource |
root |
spring.datasource.password |
Database password |
|
spring.datasource.min-idle |
Minimum number of idle connection pool threads |
5 |
spring.datasource.max-idle |
Maximum number of idle connection pool threads |
20 |
spring.datasource.max-active |
Maximum number of active database connection pool threads |
40 |
spring.datasource.validation-query |
Query to use to test a healthy connection |
select 0; |
spring.datasource.test-on-borrow |
Test the connection when a new connection is borrowed from the pool |
true |
spring.datasource.test-on-connect |
Test the connection health when connecting |
true |
spring.datasource.test-on-return |
Test the connection health on return to the pool |
true |
spring.datasource.test-while-idle |
Test the connection health of a thread while it is idle |
true |
spring.datasource.min-evictable-idle-time-millis |
Time before a connection thread is evicted from the pool if its been idle |
60000 |
spring.datasource.time-between-eviction-run-millis |
The time between runs of the eviction process |
10000 |